
现网故障案例分享-OSPF邻居反复震荡
组网介绍
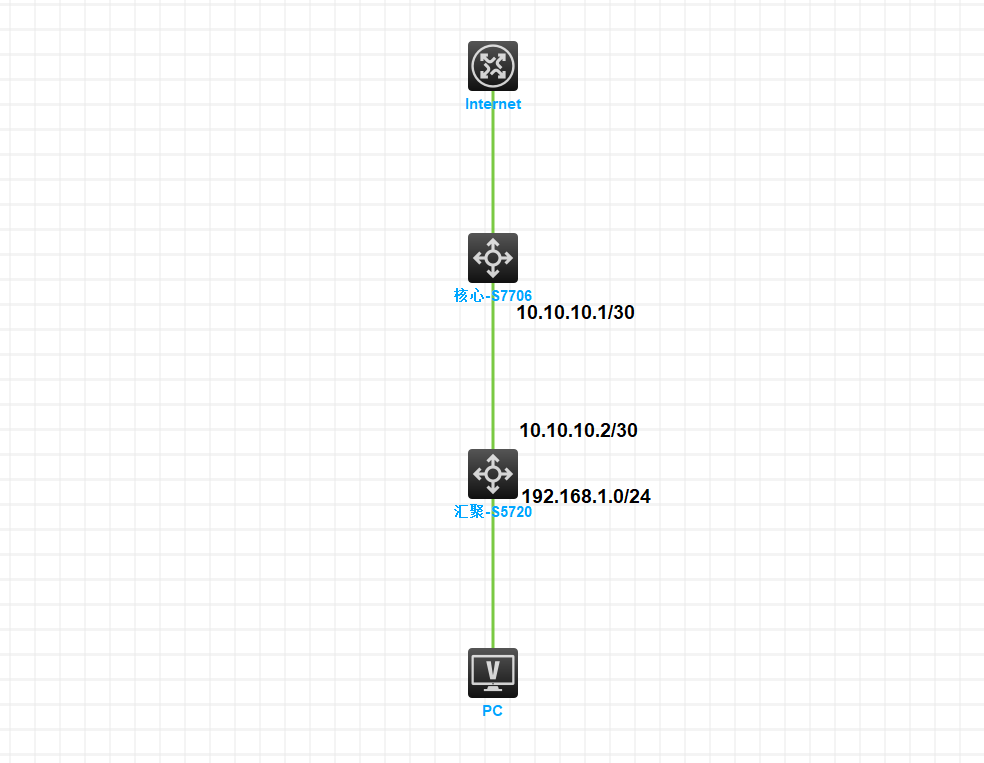
某局点S7706作为核心交换机
下方有S5720作为汇聚交换机
汇聚与核心之间跑OSPF
汇聚承载网关,向核心发布业务路由
组网拓扑如下所示:
故障现象
维护人员接到用户反馈
访问互联网出现时通时不通,并且网络异常卡顿,丢包
于是登录设备进行排查
排查思路
【1】首先查看设备告警日志,是否有提示异常,根据日志信息进行进一步的排查,如果没有则进行下一步
【2】确认出局上行链路之间是否出现拥塞、CRC错包、以及端口up/down
【2】再排查cpu利用率、内存利用率是否过高
【3】排查路由协议,是否full,路由是否有学到
处理过程
首先登录设备,查看了日志,发现一直再提示ospf neighbor down/up,从FUll状态转换为Down状态,再转换为FUll状态
OSPF: Neighbor 10.10.10.1 (GigabitEthernet0/0/1) state changed from Full to Down, reason: Dead timer expired
OSPF: Neighbor 10.10.10.1 (GigabitEthernet0/0/1) state changed from Down to Full
OSPF: Hello packet from 10.10.10.1 received, Hello interval mismatch (local 30s, remote 10s)
于是进一步排查核心与汇聚之间的OSPF配置:
S7706配置:
ospf 1 router-id 10.0.0.1
area 0.0.0.0
network 10.10.10.0 0.0.0.3
timer hello 10
timer dead 40
S5720配置:
ospf 1 router-id 10.10.10.2
area 0.0.0.0
network 10.10.10.0 0.0.0.3
network 192.168.1.0 0.0.0.255
timer hello 30
timer dead 120
发现两端OSPF的Hello报文时间不一致
核心的Hello Time发送时间周期为10秒
汇聚的Hello Time发送时间周期为30秒
再次通过命令display ospf timer hello确认
/*S7706*/
Hello interval: 10s, Dead interval: 40s
/*S5720*/
Hello interval: 30s, Dead interval: 120s
证明确实两端OSPF Hello Time时间不一致
OSPF的机制中,当邻接路由器,收不到来自邻接的Hello报文时
会启用Dead TIme的计时器,等待收到来自邻接的Hello报文信息
这里Hello报文的交互涉及到两次交互,大概需要20秒:
(0秒是首次双方互发Hello,收到后10秒重新发送邻居表包含对方的信息,对端收到后,根据Hello time,等待10秒再次发送,也就是20秒的时候发送自己包含邻居的信息给对端)
由于核心设备期望每10秒收到一次Hello报文,而汇聚每30秒才发送一次,且两端Hello时间配置不一致,导致OSPF协议无法协商建立稳定的邻居关系
并且核心设备在连续40秒未收到Hello报文时触发Dead Timer超时,判定邻居失效,从而引发邻居状态反复震
在日志中就呈现了OSPF反复从FULL转变为DOWN,又从DOWN转变为FULL状态
解决方案
显而易见,将汇聚的Hello Time&Dead Time时间周期修改为和核心一致的10秒和40秒
S5720配置:
ospf 1 router-id 10.10.10.2
area 0.0.0.0
network 10.10.10.0 0.0.0.3
network 192.168.1.0 0.0.0.255
timer hello 10 /*修改成10秒*/
timer dead 40 /*修改成40秒*/
如果需要加快OSPF的故障收敛
还可以配置BFD来联动OSPF
文章作者:Magic清风
文章链接:https://skylan.cc/archives/1757210133201
版权声明:本博客所有文章除特别声明外,均采用CC BY-NC-SA 4.0 许可协议,转载请注明出处!
评论